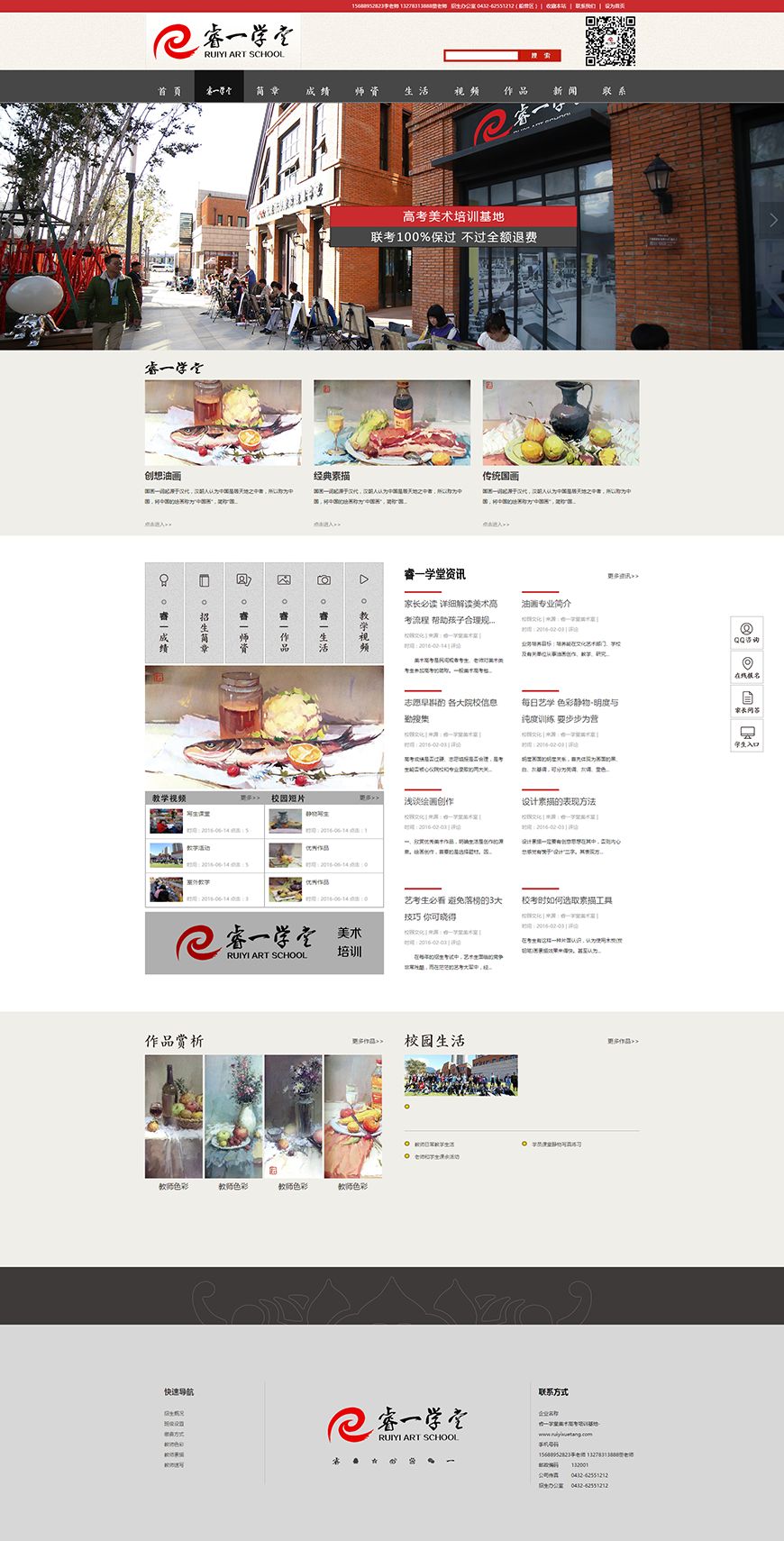
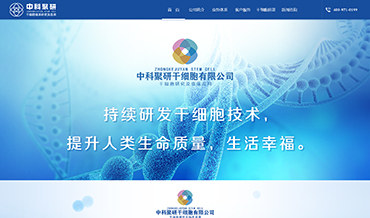
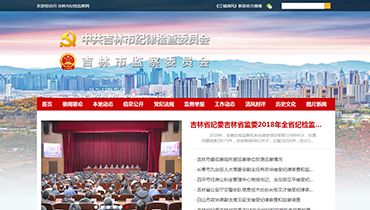
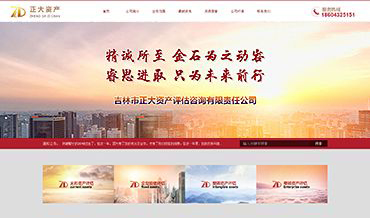

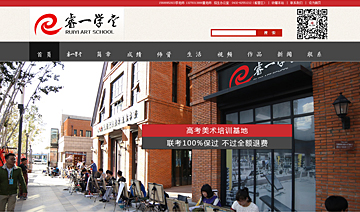
����Dѧ��ѡַ�����з������ϲ��³��ɻ����³ǣ��ɽ���·488�ţ����ڼ������ɻ�������ӵŨ���������������Ϣ��У���ܷ����������ڽ������ռ䡢���̻�����Ȼ������һ��IJ��֣���ֿ�����ѧ������ѧϰ�������ԡ�ѧУ��ȡ���ʽ������ʳ��һ�塣��ѧ¥�����ᡢ�����������е�Ӳ����ʩ�뱸��������ȫ��Ϊݷݷѧ���ṩ�����õ�ѧϰ���������
���������繫˾,��������վ����,��������վ����,��������ҳ���,������С����,��������С����,�������Ź��ں�,��������������,����������վ�ļҺ�